Building Robust Web Automation with Selenium and Python

Automation of the web is now an indispensable tool in modern software development and testing. In this comprehensive Selenium Python tutorial, you’ll learn how to build a robust web automation framework capable of handling real-world scenarios. If you are interested in implementing automated testing in Python or creating complex web scraping automation solutions, this guide will give you industry-tested approaches and Selenium best practices.
Understanding Web Automation Fundamentals
Web automation is vital in modern software development, testing, and data collection. Its applications span from end-to-end testing of web applications to simplifying repetitive workflows, such as form submissions or web scraping. While Selenium WebDriver Python integration offers powerful capabilities, robust web automation is more than just writing scripts to mimic user interactions. It’s about designing workflows and frameworks that are maintainable, adaptable, and resilient to changes to the target web application.
Below are the key aspects we’ll cover throughout this tutorial:
- Selecting appropriate locators (XPath, CSS, etc.)
- Dynamic elements and state loading
- Implementing retry mechanisms
- Managing browser sessions properly
- Maintainability structure of code
We will build a web scraping automation project for a price tracker on e-commerce websites using Books to Scrape as a demo site to demonstrate these concepts while adhering to Selenium best practices.
Prerequisites
To follow along with this tutorial, you’ll need:
- Python 3.x installed on your machine.
- Basic knowledge of Python programming
- Basic knowledge of Web Scrapping with Selenium
The code for this tutorial is available on our github repository, feel free to clone it to follow along.
Setting Up the Development Environment
Let’s set up a proper development environment and install the necessary Python packages. First, create the project folder, and a new virtual environment by running the commands below:
mkdir price_tracker_automation && cd price_tracker_automation
python3 -m venv env
source env/bin/activateThen, create and add the following Python packages to your requirements.txt file:
selenium==4.16.0
webdriver-manager==4.0.1
python-dotenv==1.0.0
requests==2.31.0In the above code, we defined our core dependencies. The selenium package provides the foundation for our web automation framework, while webdriver-manager handles browser driver management automatically. The python-dotenv package is for environment configuration, and the requests package is for HTTP requests handling.
Now run the command below to install all the Python packages in your requirements.txt file by running the command below:
pip install -r requirements.txtLastly, create the following folder structure for our project:
price_tracker_automation/
├── core/
│ ├── browser.py
| ├── scraper.py
│ └── element_handler.py
├── database/
│ └── db_manager.py
├── notifications/
| └── price_alert.py
├── requirements.txt
├── run.py
└── main.pyHere we establish a modular project structure following software engineering best practices. The core directory contains our primary automation components, while database handles data persistence.
Building the Price Tracker Tool
With the project environment, dependencies, and folder structures created, let’s proceed to build the price tracker automation tool using Selenium and Python.
Implementing our Browser Management System
Let’s implement our browser management system, this is an important component for stable Selenium WebDriver Python integration. Add the code snippet below to your core/browser.py file:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support import expected_conditions as EC
import logging
class BrowserManager:
def __init__(self, headless=False):
self.options = webdriver.ChromeOptions()
if headless:
self.options.add_argument('--headless')
# Add additional stability options
self.options.add_argument('--no-sandbox')
self.options.add_argument('--disable-dev-shm-usage')
self.options.add_argument('--disable-gpu')
self.driver = None
self.logger = logging.getLogger(__name__)The above code creates a BrowserManager class that handles WebDriver initialization and configuration. The class implements Selenium best practices by configuring Chrome options for stability and performance. The headless parameter allows for running tests without a visible browser window, which is crucial for CI/CD pipelines.
Now add the following methods to the BrowserManager class to implement the core browser management features:
def start_browser(self):
"""Initialize and return a ChromeDriver instance"""
try:
service = webdriver.ChromeService()
self.driver = webdriver.Chrome(service=service, options=self.options)
self.driver.implicitly_wait(10)
return self.driver
except Exception as e:
self.logger.error(f"Failed to start browser: {str(e)}")
raise
def close_browser(self):
"""Safely close the browser"""
if self.driver:
self.driver.quit()
self.driver = NoneIn the above code, the start_browser method uses webdriver-manager to automatically handle driver installation and updates, while close_browser ensures proper resource cleanup. The implementation includes an implicit wait configuration to handle dynamic page loading gracefully.
Creating an Element Handler
Next, let’s proceed to implement the element interaction system, this is important in any web automation framework because it enables us to detect and interact with elements in a reliable way while following Selenium’s best practices. Add the code snippets to your core/element_handler.py
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, StaleElementReferenceException
class ElementHandler:
def __init__(self, driver, timeout=10):
self.driver = driver
self.timeout = timeoutIn the above code, we created an ElementHandler class, which encapsulates Selenium WebDriver Python interaction patterns. The class accepts a WebDriver instance and configurable timeout parameter.
Update your ElementHandler class to add core element interaction methods:
def wait_for_element(self, locator, timeout=None):
"""Wait for element with retry mechanism"""
timeout = timeout or self.timeout
try:
element = WebDriverWait(self.driver, timeout).until(
EC.presence_of_element_located(locator)
)
return element
except TimeoutException:
raise TimeoutException(f"Element {locator} not found after {timeout} seconds")
def get_text_safely(self, locator, timeout=None):
"""Safely get text from element with retry mechanism"""
max_retries = 3
for attempt in range(max_retries):
try:
element = self.wait_for_element(locator, timeout)
return element.text.strip()
except StaleElementReferenceException:
if attempt == max_retries - 1:
raise
continueThe above methods use Selenium’s WebDriverWait and expected_conditions to detect elements so that it can also handle dynamic web pages where the elements may load asynchronously.
Add another method to implement the text extraction logic:
def get_text_safely(self, locator, timeout=None):
"""Safely get a text from the element with retry mechanism"""
max_retries = 3
for attempt in range(max_retries):
try:
element = self.wait_for_element(locator, timeout)
return element.text.strip()
except StaleElementReferenceException:
if attempt == max_retries - 1:
raise
continueThe method includes retry logic to handle StaleElementReferenceException, which is a common challenge in web automation.
Implementing the Price Tracker Core
Now let’s build our main scraping functionality, incorporating automated testing Python concepts and robust error handling. Add the code snippets below to your core/scraper.py file:
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from datetime import datetime
import logging
class BookScraper:
def __init__(self, browser_manager, element_handler):
self.browser = browser_manager
self.handler = element_handler
self.base_url = "http://books.toscrape.com"
# Define locators
self.LOCATORS = {
'book_title': (By.CSS_SELECTOR, "div.product_main h1"),
'book_price': (By.CSS_SELECTOR, "p.price_color"),
'stock_status': (By.CSS_SELECTOR, "p.availability"),
'category': (By.CSS_SELECTOR, "ul.breadcrumb li:nth-child(3) a")
}In the above code, we created the BookScraper class that integrates our browser and element handling components. The class follows the Page Object Model pattern, a key concept in web automation framework design, by centralizing element locators and providing a clean API for scraping operations.
Next, update the BookScraper class to add the core product data extraction methods:
def extract_product_data(self, url):
"""Extract product information with robust error handling"""
try:
self.browser.driver.get(url)
# Initialize product data dictionary
product_data = {
'url': url,
'timestamp': datetime.now().isoformat(),
'success': True
}
# Extract each field with proper error handling
for field, locator in self.LOCATORS.items():
try:
value = self.handler.get_text_safely(locator)
product_data[field] = value
except Exception as e:
self.logger.error(f"Error extracting {field}: {str(e)}")
product_data[field] = None
product_data['success'] = False
# Clean price data
if product_data.get('book_price'):
product_data['book_price'] = self.clean_price(
product_data['book_price']
)
return product_data
except Exception as e:
self.logger.error(f"Failed to scrape {url}: {str(e)}")
return {
'url': url,
'timestamp': datetime.now().isoformat(),
'success': False,
'error': str(e)
}
def clean_price(self, price_str):
"""Clean and convert price string to float"""
try:
return float(price_str.replace('£', '').strip())
except ValueError:
self.logger.error(f"Failed to parse price: {price_str}")
return NoneThe above methods uses a structured approach to gather product information, maintaining detailed logs for debugging and monitoring.
Setting Up Database Management
Let’s implement the database layer of our web automation framework, which will handle the persistent storage of our scraped data. This component will allow us to track the price changes over time. Add the code snippets below to your database/db_manager.py:
import sqlite3
from datetime import datetime
import logging
class DatabaseManager:
def __init__(self, db_path="price_tracker.db"):
self.db_path = db_path
self.logger = logging.getLogger(__name__)
self.setup_database()In the above code, we defined our DatabaseManager class that handles all database operations. We used SQLite for simplicity and portability, to avoid having to set up and configure a database and SQLite is also ideal for our web scraping automation project since we are not storing large amounts of data.
Next, update your database/db_manager.py to add the database initialization method:
def setup_database(self):
""" Initialize database with required tables"""
try:
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
# Create products table
cursor.execute('''
CREATE TABLE IF NOT EXISTS products (
id INTEGER PRIMARY KEY AUTOINCREMENT,
url TEXT UNIQUE,
title TEXT,
category TEXT,
first_seen TIMESTAMP,
last_updated TIMESTAMP
)
''')
# Create price history table
cursor.execute('''
CREATE TABLE IF NOT EXISTS price_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
product_id INTEGER,
price REAL,
stock_status TEXT,
timestamp TIMESTAMP,
FOREIGN KEY (product_id) REFERENCES products (id)
)
''')
conn.commit()
except sqlite3.Error as e:
self.logger.error(f"Database setup failed: {str(e)}")
raiseHere we establish our database schema using SQL DDL statements, and create separate tables for products and price history, with appropriate relationships and constraints which will enable us to track price and perform historical analysis on the data we store.
Now let’s add another method to save data to the database:
def save_product_data(self, data):
"""Save or update product data and price history"""
try:
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
# Insert or update product
cursor.execute('''
INSERT INTO products (url, title, category, first_seen, last_updated)
VALUES (?, ?, ?, ?, ?)
ON CONFLICT(url) DO UPDATE SET
title = ?,
category = ?,
last_updated = ?
''', (
data['url'],
data['book_title'],
data['category'],
datetime.now(),
datetime.now(),
data['book_title'],
data['category'],
datetime.now()
))
# Get product_id
cursor.execute('SELECT id FROM products WHERE url = ?', (data['url'],))
product_id = cursor.fetchone()[0]
# Insert price history
cursor.execute('''
INSERT INTO price_history (product_id, price, stock_status, timestamp)
VALUES (?, ?, ?, ?)
''', (
product_id,
data['book_price'],
data['stock_status'],
data['timestamp']
))
conn.commit()
except sqlite3.Error as e:
self.logger.error(f"Failed to save product data: {str(e)}")
raiseIn the above code, we implemented the data persistence logic using parameterized queries to prevent SQL injection. The method handles both insert and update operations using SQLite’s ON CONFLICT clause.
Main Application Integration
Let’s tie everything together with our main application class, incorporating all elements of our Selenium WebDriver Python implementation. Add the code snippets below to your main.py file:
from core.browser import BrowserManager
from core.element_handler import ElementHandler
from core.scraper import BookScraper
from database.db_manager import DatabaseManager
import time
import logging
class PriceTracker:
def __init__(self):
self.browser_manager = BrowserManager(headless=True)
self.driver = self.browser_manager.start_browser()
self.element_handler = ElementHandler(self.driver)
self.scraper = BookScraper(self.browser_manager, self.element_handler)
self.db_manager = DatabaseManager()
self.logger = logging.getLogger(__name__)
In the above code, we create the main PriceTracker class that orchestrates all components of our web scraping automation solution. The PriceTracker class follows dependency injection patterns to maintain modularity and testability.
Next, update our PriceTracker class to add the core tracking methods:
def track_product(self, url):
"""Track a single product's price"""
try:
self.logger.info(f"Tracking product: {url}")
product_data = self.scraper.extract_product_data(url)
if product_data['success']:
self.db_manager.save_product_data(product_data)
self.logger.info(f"Successfully tracked product: {url}")
else:
self.logger.error(f"Failed to track product: {url}")
except Exception as e:
self.logger.error(f"Error tracking product {url}: {str(e)}")Here we implemented the main product tracking logic that handles the web scraping and stores the scraped data.
Running the Application
Let’s create an execution script to run our automation script. Add the following code snippets to your run.py file:
def main():
parser = argparse.ArgumentParser(description='Book Price Tracker')
parser.add_argument(
'--urls',
nargs='+',
help='URLs of books to track',
default=[
"http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html",
"http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html"
]
)
args = parser.parse_args()
setup_logging()
logger = logging.getLogger(__name__)
try:
logger.info("Initializing price tracker...")
tracker = PriceTracker()
logger.info("Starting price tracking...")
for url in args.urls:
tracker.track_product(url)
logger.info(f"Successfully processed: {url}")
logger.info("Price tracking completed successfully")
except Exception as e:
logger.error(f"Critical error during execution: {str(e)}")
import traceback
logger.error(traceback.format_exc())Now run the following command on your terminal to run the script:
python run.py
# or run this if you want to specify your own urls
python run.py --urls \
"http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html" \
"http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html" \
"http://books.toscrape.com/catalogue/soumission_998/index.html"The above command will show the output on the screenshot below:
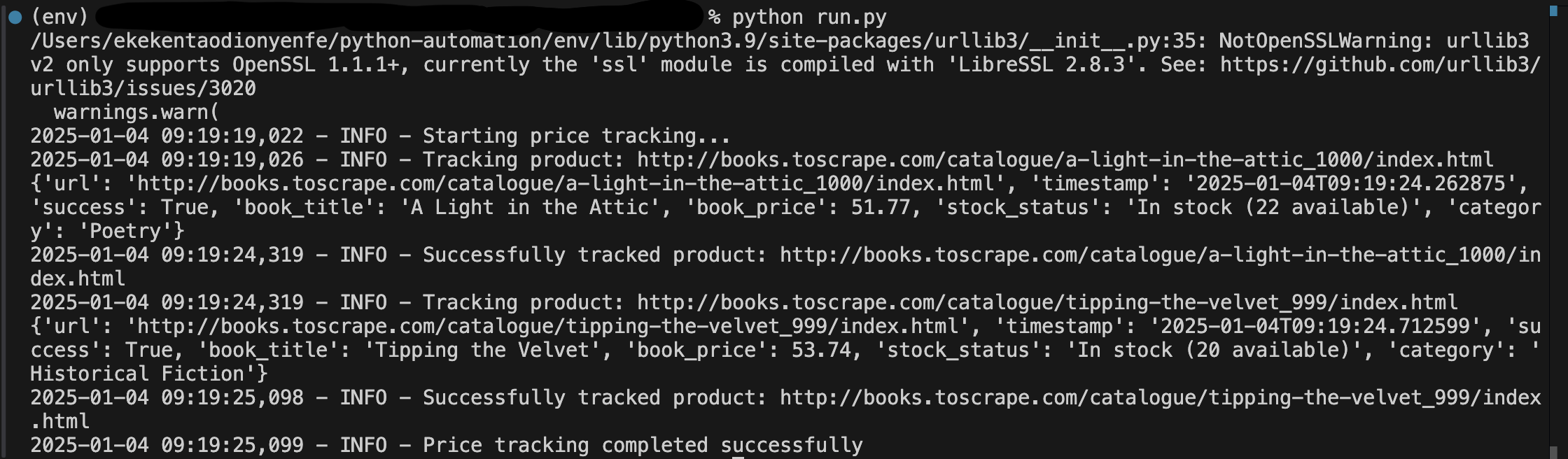
From the above script, you can see that our automation script is tracking the price for all the specified URLs.
Tracks Price Change
Our current implementation only tracks and saves product prices. After tracking prices, let’s enhance our price tracker to notify users about price changes. Add the following code snippets to your notifications/price_alert.py file:
from email.mime.text import MIMEText
import smtplib
import logging
from datetime import datetime, timedelta
class PriceAlertManager:
def __init__(self, db_manager):
self.db_manager = db_manager
self.logger = logging.getLogger(__name__)
def check_price_changes(self, threshold_percent=5):
"""Check for significant price changes"""
with sqlite3.connect(self.db_manager.db_path) as conn:
cursor = conn.cursor()
# Get latest and previous prices for all products
cursor.execute('''
SELECT
p.title,
ph1.price as current_price,
ph2.price as previous_price,
p.url
FROM products p
JOIN price_history ph1 ON p.id = ph1.product_id
LEFT JOIN price_history ph2 ON p.id = ph2.product_id
WHERE ph1.timestamp = (
SELECT MAX(timestamp)
FROM price_history
WHERE product_id = p.id
)
AND ph2.timestamp = (
SELECT MAX(timestamp)
FROM price_history
WHERE product_id = p.id
AND timestamp < ph1.timestamp
)
''')
price_changes = []
for row in cursor.fetchall():
title, current_price, previous_price, url = row
if previous_price: # Skip first-time prices
change_percent = ((current_price - previous_price) / previous_price) * 100
if abs(change_percent) >= threshold_percent:
price_changes.append({
'title': title,
'url': url,
'old_price': previous_price,
'new_price': current_price,
'change_percent': change_percent
})
return price_changesIn the above code snippet, we created a PriceAlertManager class with essential dependencies. The manager takes a database manager instance as a parameter and sets up logging for tracking alert operations. The class uses complex joins to compare current and previous prices. Then we implemented a dynamic price change percentage computation and created a structured dictionary for price change information.
Next, update your PriceAlertManager class to add an email notification functionality:
def send_price_alerts(self, email_config, price_changes):
"""Send email alerts for price changes"""
if not price_changes:
return
# Create email content
email_body = "Price Change Alerts:\n\n"
for change in price_changes:
email_body += f"""
Product: {change['title']}
Old Price: £{change['old_price']:.2f}
New Price: £{change['new_price']:.2f}
Change: {change['change_percent']:.1f}%
URL: {change['url']}
-------------------
"""
msg = MIMEText(email_body)
msg['Subject'] = f'Price Alert: {len(price_changes)} products changed'
msg['From'] = email_config['sender']
msg['To'] = email_config['recipient']
try:
with smtplib.SMTP(email_config['smtp_server'], email_config['smtp_port']) as server:
server.starttls()
server.login(email_config['username'], email_config['password'])
server.send_message(msg)
self.logger.info(f"Price alerts sent for {len(price_changes)} products")
except Exception as e:
self.logger.error(f"Failed to send price alerts: {str(e)}")Here, we created an email notification using Python’s email and SMTP libraries. The implementation uses the MIMEText class to create properly formatted email messages. The email body is dynamically generated using f-strings, incorporating detailed price change information with precise currency formatting.
Now let’s modify our run script to include price alerts:
#...
from notifications.price_alert import PriceAlertManager
#...
def main():
#...
tracker = PriceTracker()
alert_manager = PriceAlertManager(tracker.db_manager)
try:
logger.info("Starting price tracking...")
for url in args.urls:
tracker.track_product(url)
time.sleep(2) # Be nice to the server
logger.info("Price tracking completed successfully")
# Check for price changes
price_changes = alert_manager.check_price_changes(threshold_percent=5)
if price_changes:
# Email configuration
email_config = {
'sender': '[email protected]',
'recipient': '[email protected]',
'smtp_server': 'smtp.gmail.com',
'smtp_port': 587,
'username': '[email protected]',
'password': 'your-app-password'
}
# Send alerts
alert_manager.send_price_alerts(email_config, price_changes)
except Exception as e:
logger.error(f"Error during price tracking: {str(e)}")
finally:
tracker.cleanup()
Now if you run the script again, it will track the product prices and alert you of the products whose prices have changed like in the screenshot below:
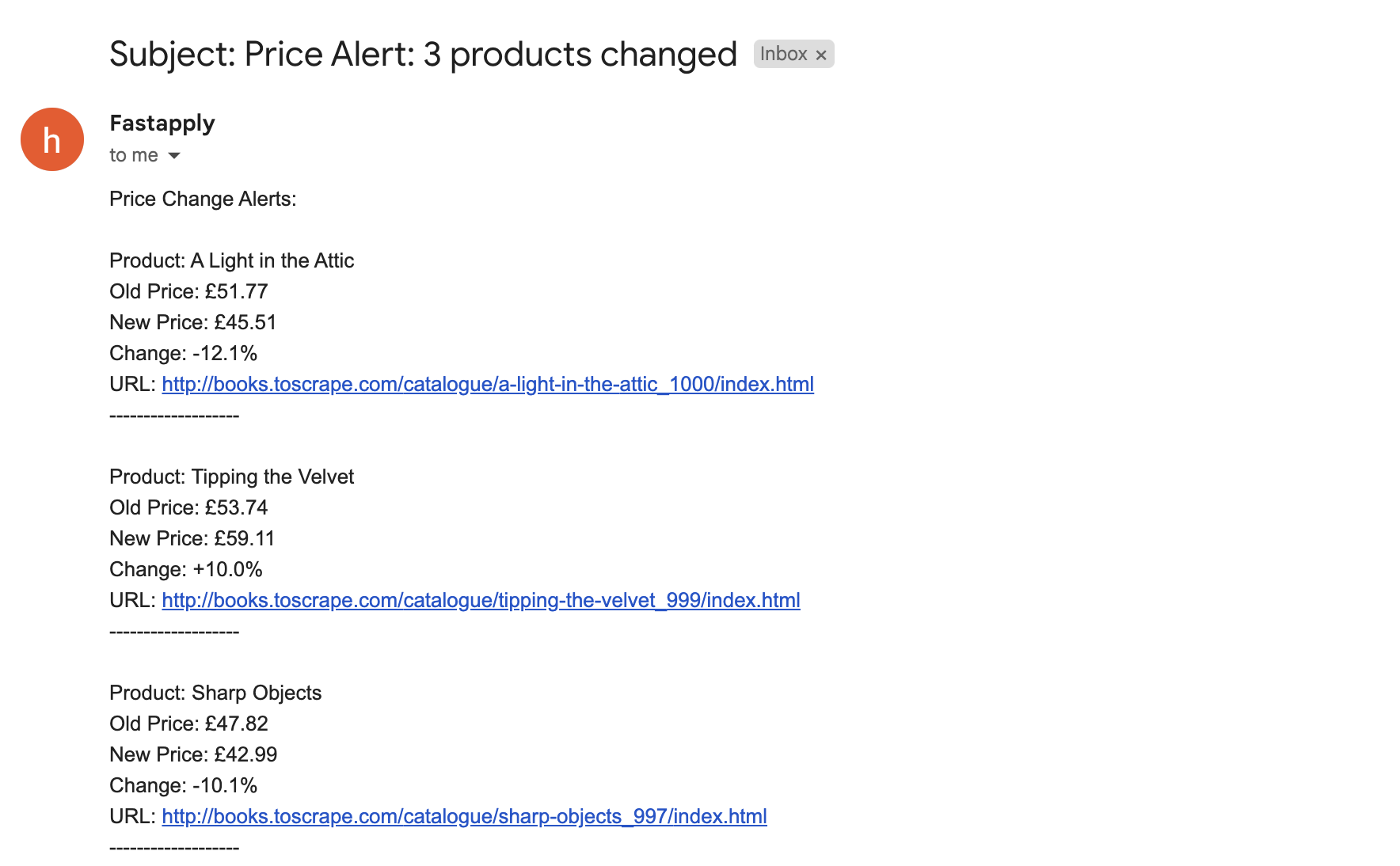
Perhaps you can run this script in a cron job to track the prodcuts prices and alert you in real-time of the price changes without having to manually run it everytime. Eg.
0 */6 * * * python run.py --urls \ "http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html" \ "http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html" \ "http://books.toscrape.com/catalogue/soumission_998/index.html"
Conclusion
Throughout this tutorial, you’ve learned how to build a robust web automation tool using Selenium and Python. We started by understanding the web automation fundamentals, then we set up a development eviroment for the Price Traker tool we built for the demonstrations in this tutorial. Then we went futher to build the Price tracker application that tracks prices of products and alerts users of the price changes. Now that you have this knowledge, what tool would you be building next. Let me know in the comments section. Happy coding!
#selenium-python
#web-automation
#selenium-webdriver
#automated-testing
#python-automation
#web-scraping
#test-framework
#automation-architecture

FastApply Team
AI/ML Engineers